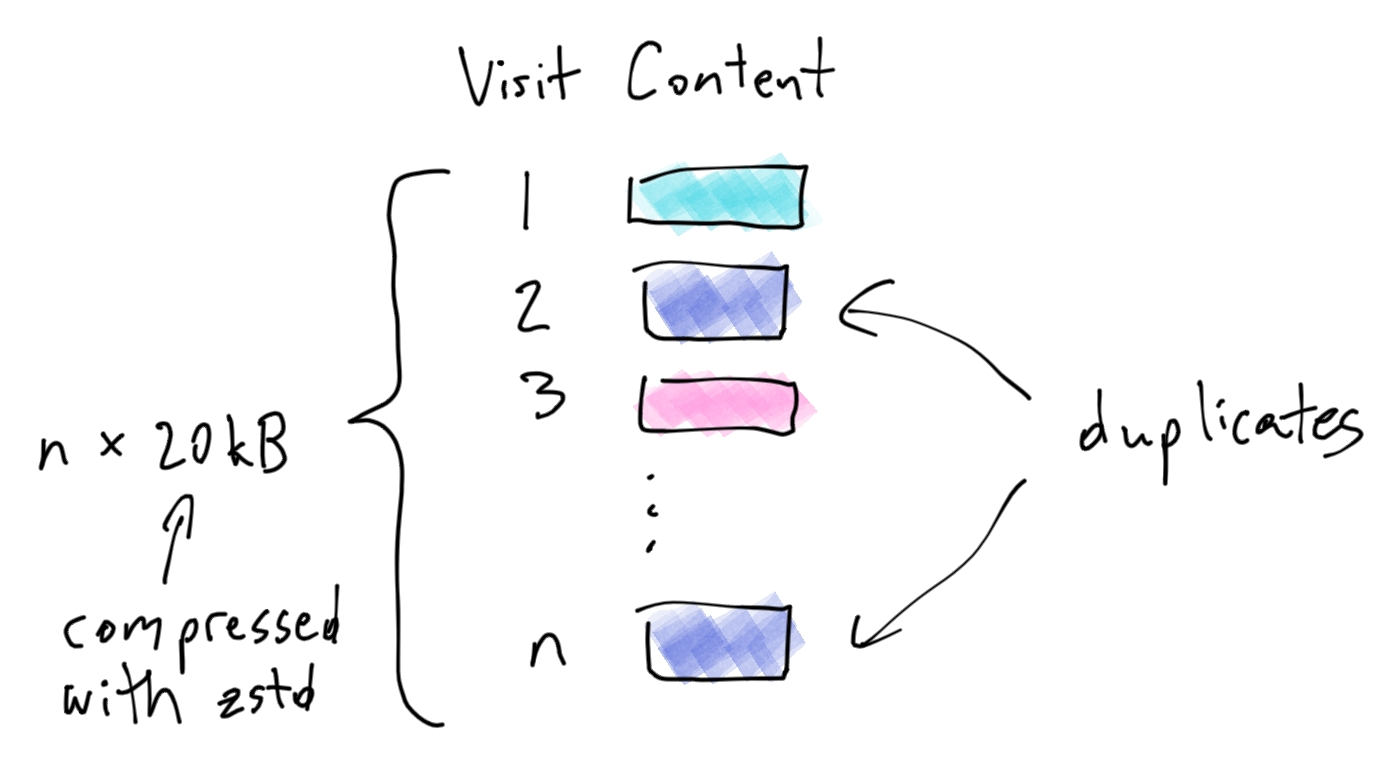
Moment has a problem: we don't have enough customers. I've recently made solving this my full-time job. "But Serge, you're the CEO! Shouldn't that always have been your full-time job?" I hear you asking. Yes, but I'm a moron[1].
Anyway, enough about me. Let's talk about you, dear founder.
You tend to be opinionated and vocal. It's why you became a founder in the first place. You couldn't stand working for the corporate blob. The rigidity and layers of bureaucracy are suffocating. And even if you could tolerate the blob, the blob couldn't tolerate you. At least not over the long term. Your willingness to ask hard questions and point out uncomfortable truths would be seen as merely annoying at first, but in time, would trigger the corporate gag reflex. You would simply not fit in. All that to say, you are exactly the right person to give feedback