
Content-defined chunking runs approximately as fast as gzip and can achieve compression ratios better than 100:1 on certain classes of data.[1]
Suppose we have several webpages that frequently get updated, and we want to store every update of every page. The most naive way to do it would be to make a full copy of the visited page every time, and use a standard compression algorithm like zstd on each copy. For simplicity, let's say that each page is about 100kB and that the compression ratio of zstd on the typical page is 5:1.[2]
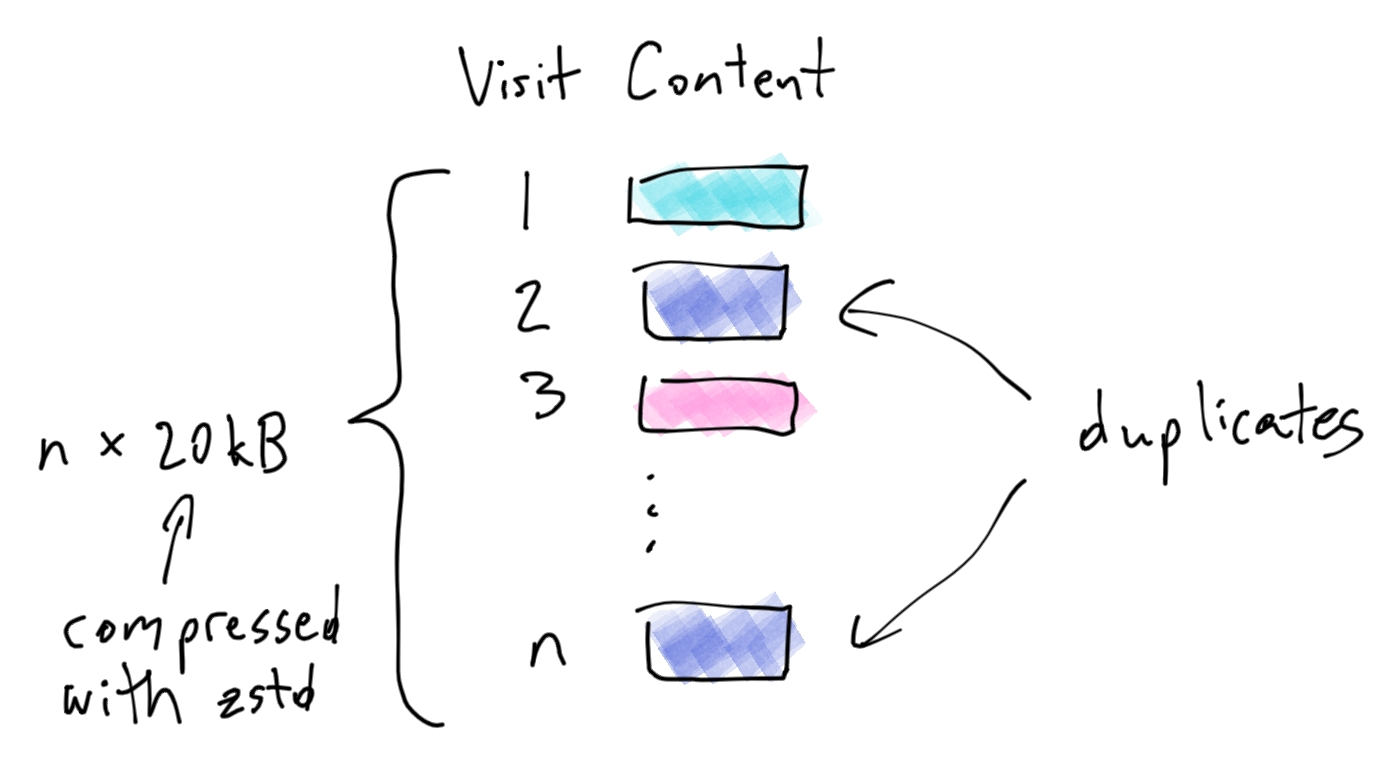
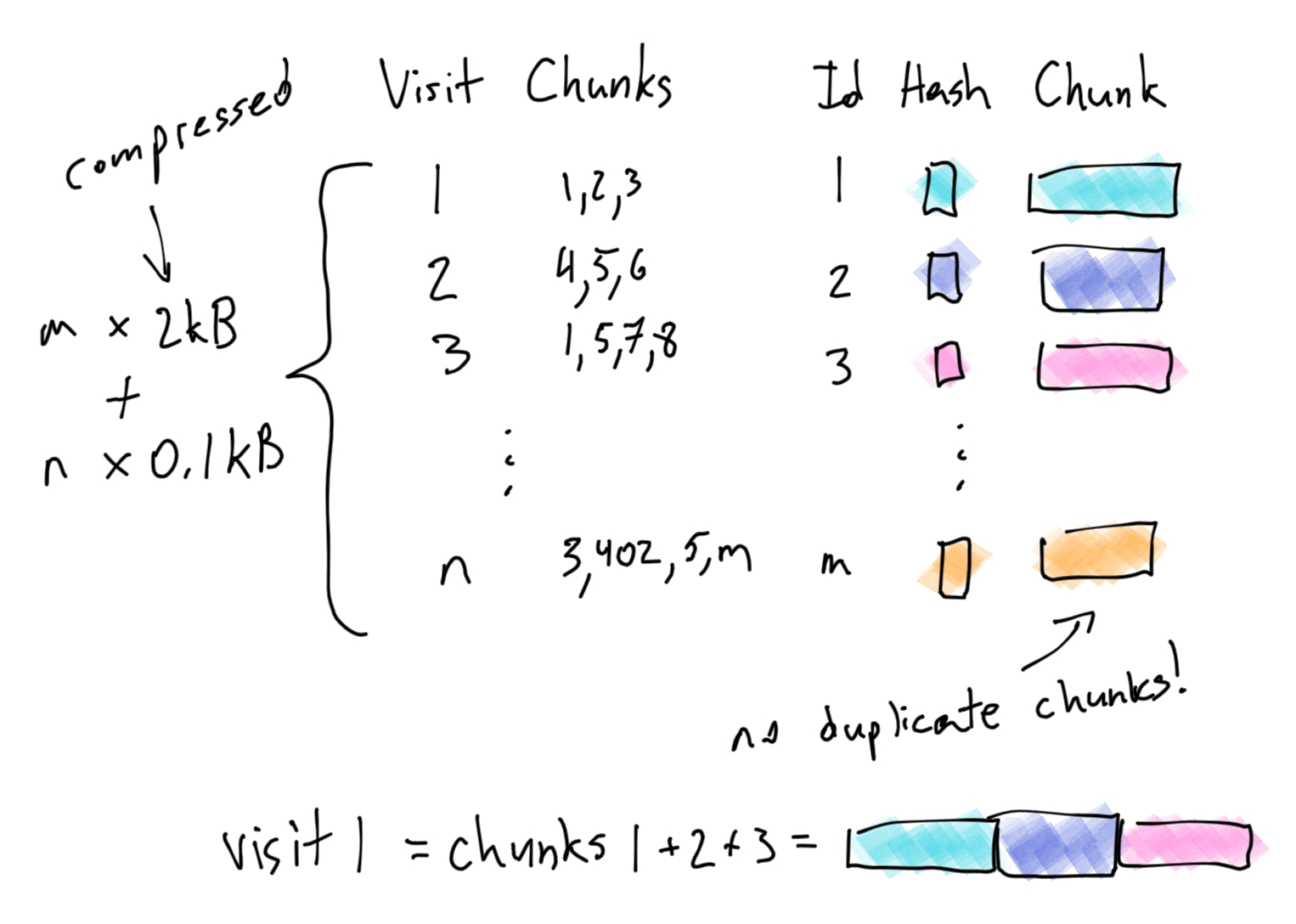
To store n updates, we would require n * 20kB of storage. Can we do better? We notice that occasionally, one of the updates is identical to a previous one. That sounds like an opportunity to improve. Before saving, we hash the content to check for duplication. We only save the content and hash to the database if we could not find a duplicate.
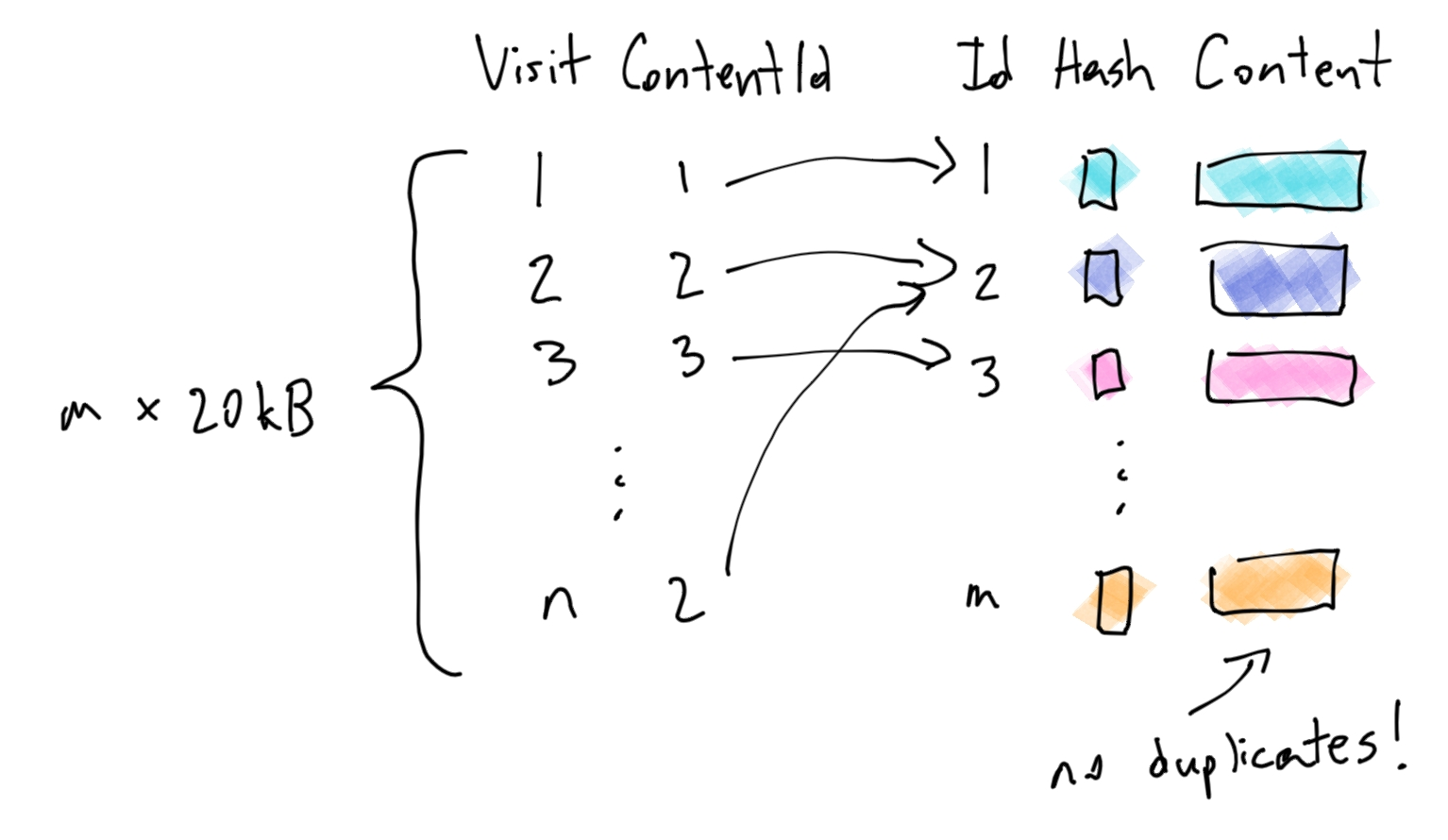
This is definitely better – we only store the 20kB[3] when we get a unique update. But we can go even further. We notice that often, an update is very close, but not exactly the same, as a previous update. For example, a store page might update the price of an item, and nothing else.
Aha! We can split the 100kB page into 10kB chunks, and store each chunk. We would store the page as just a list of ordered chunk ids. When we need to reconstruct a page, we can get all of its chunks and splice them together.
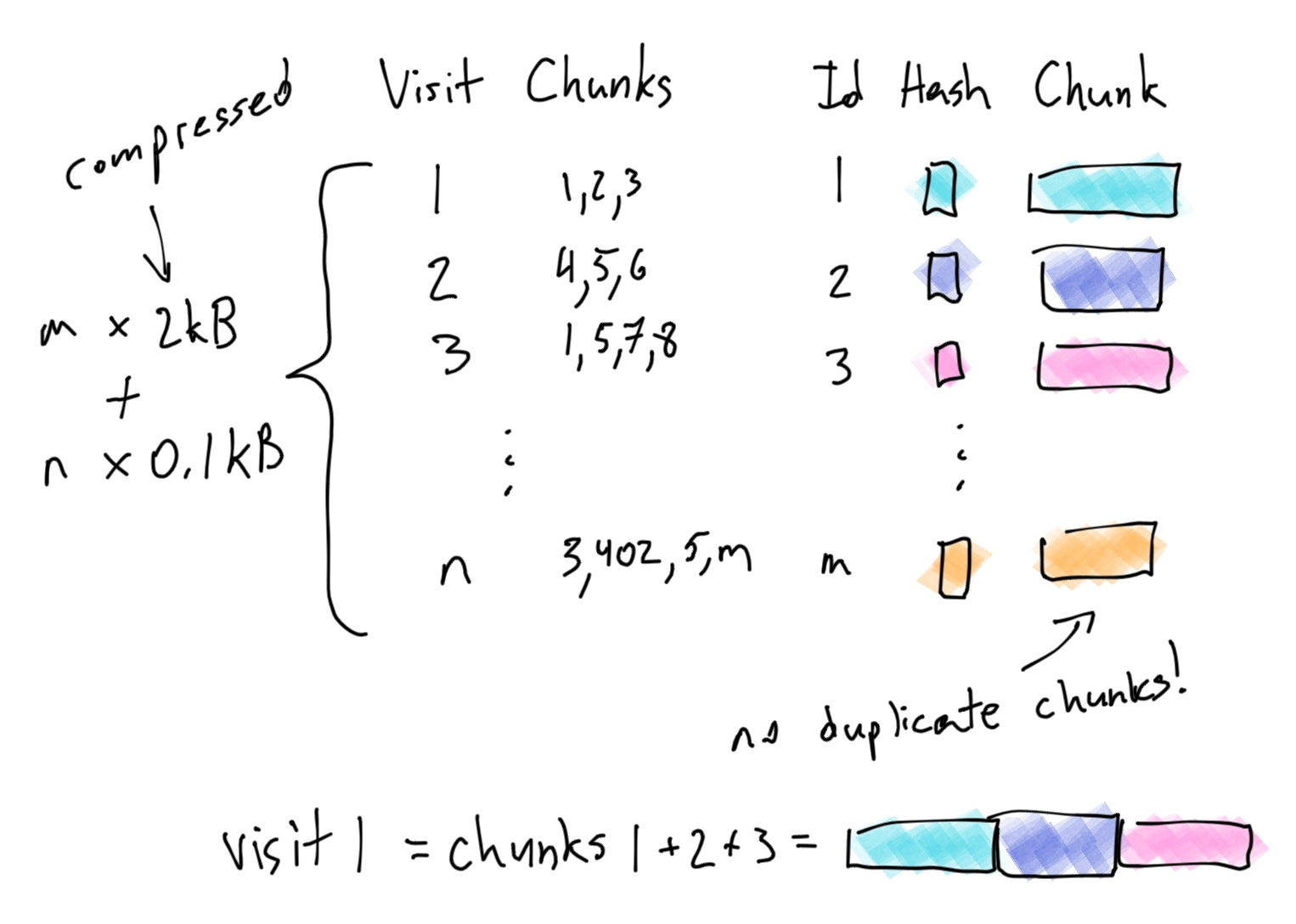
Note that we still need to store a hash for each chunk in order to quickly check if a given chunk already exists.
Now, if the price changes from $8.99 to $9.99, we don't need save the full page, we just save the single 10kB chunk that contained the price. All of the other chunks remain the same!

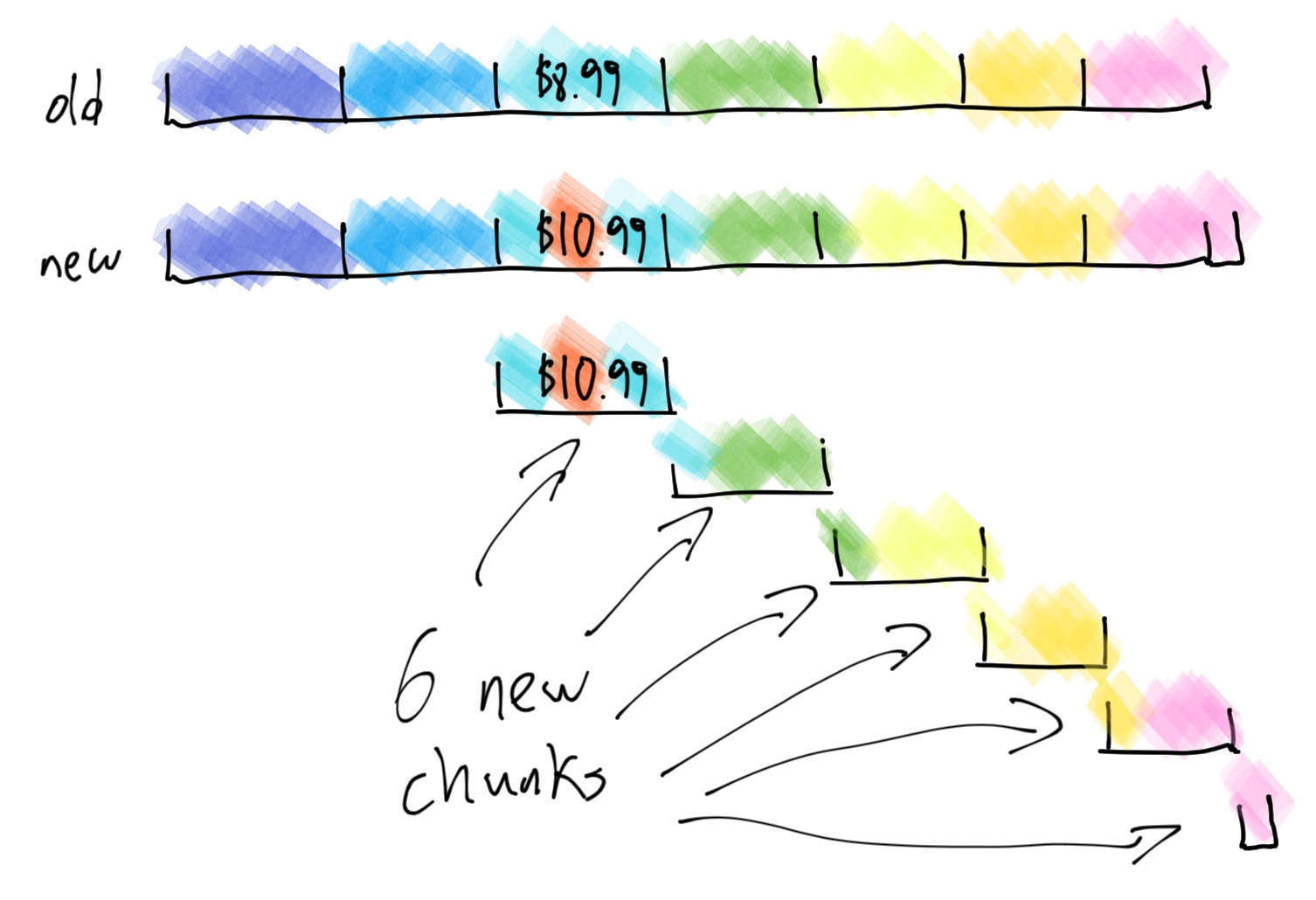
After implementing this, we come across a problem. Suppose one of the store items has its price changed from $8.99 to $10.99, keeping all other content the same. The extra digit in the 10 causes all of the chunk boundaries to shift by 1 byte. The page inserted just a single byte, but we are forced to save a new copy of every chunk that follows that byte!
We need a better strategy. What if, instead of using fixed-size chunks, we used variable-sized chunks that depend on the content? For example, we might declare the beginning of a new chunk every time we come across the following characters: <div.
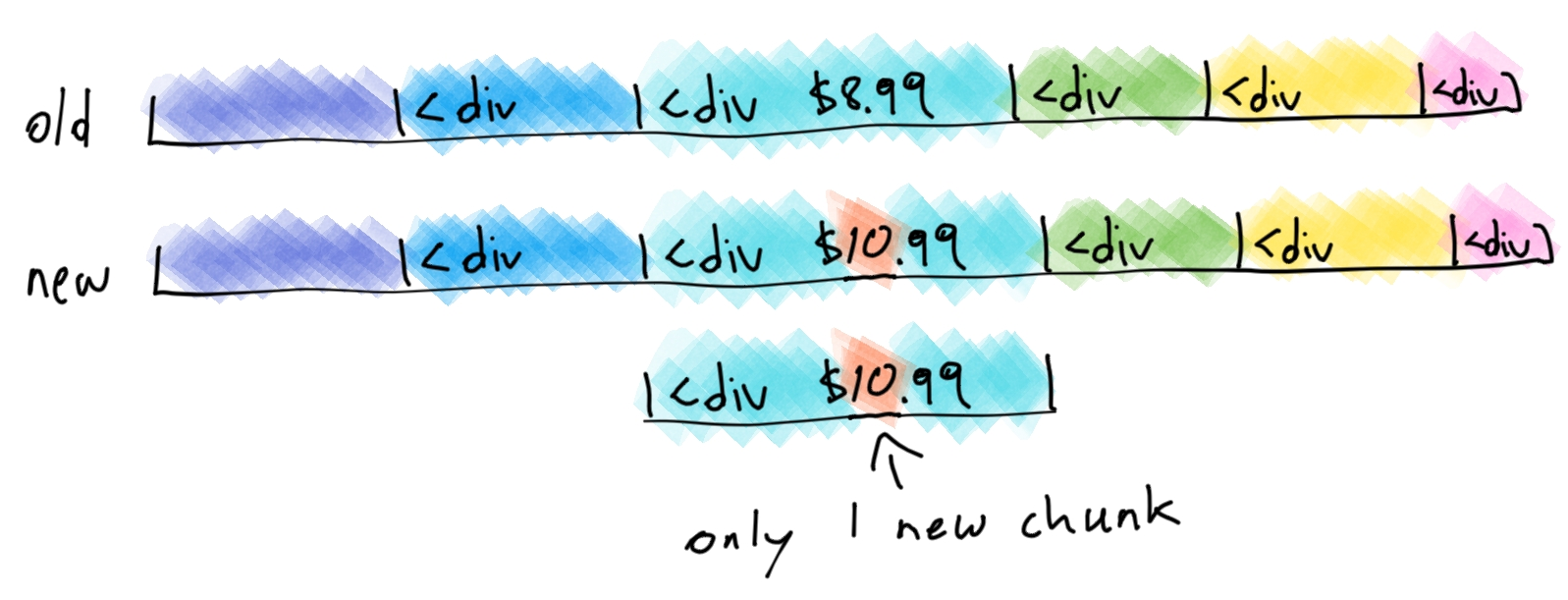
On the first page, this works really well. It has only 12 divs, and they are pretty evenly spaced out. Very quickly, though, we run into more problems. Some pages use <divs gratuitously. We end up with lots of very small chunks. This worsens our compression because the hashes of such chunks are larger than the chunks themselves! Perhaps we can impose a minimum chunk size of 1kB. That way, even if there are many <divs close together, we will still have reasonably sized chunks.
But there's another problem. Some pages don't use <divs at all – we have to store the entire page in a single chunk. How can we force a page to have "nice" chunks, when those chunks are based on the content?
Here's an idea. We read the page byte-by-byte. As we are reading, we can hash everything from the start of the current chunk up to the current byte. When we encounter a hash whose first two bytes are less than 00 06, we declare the end of the current chunk.
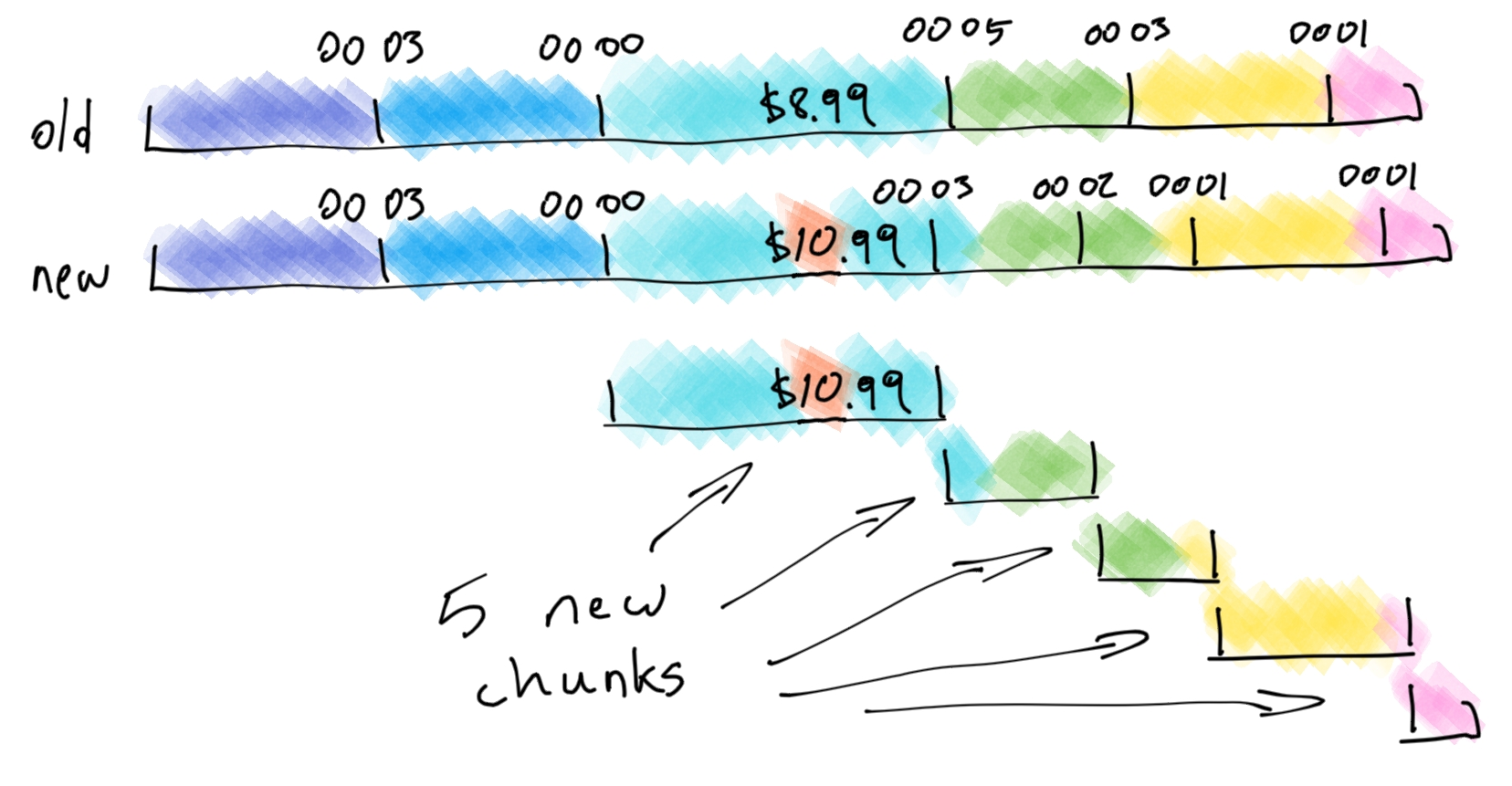
This doesn't quite work. The hash does act to uniformly distribute the chunk boundaries, as we expected. But whenever any of the content in a chunk changes, its end boundary also changes. Which means that the next chunk's content also changes, which means that its end boundary also changes, etc. A single chunk changing its boundary cascades into all the following chunks!
We need the chunk boundaries to stay relatively stable, even if there are changes to the content of the chunk. We can use a clever trick: instead of using the entire chunk to generate a hash, we just use just the trailing 64 bytes. That should be enough to get a good distribution of boundaries, but now a boundary doesn't move unless a change occurs very close to it. And even when a boundary does move, it doesn't cascade into the following ones.
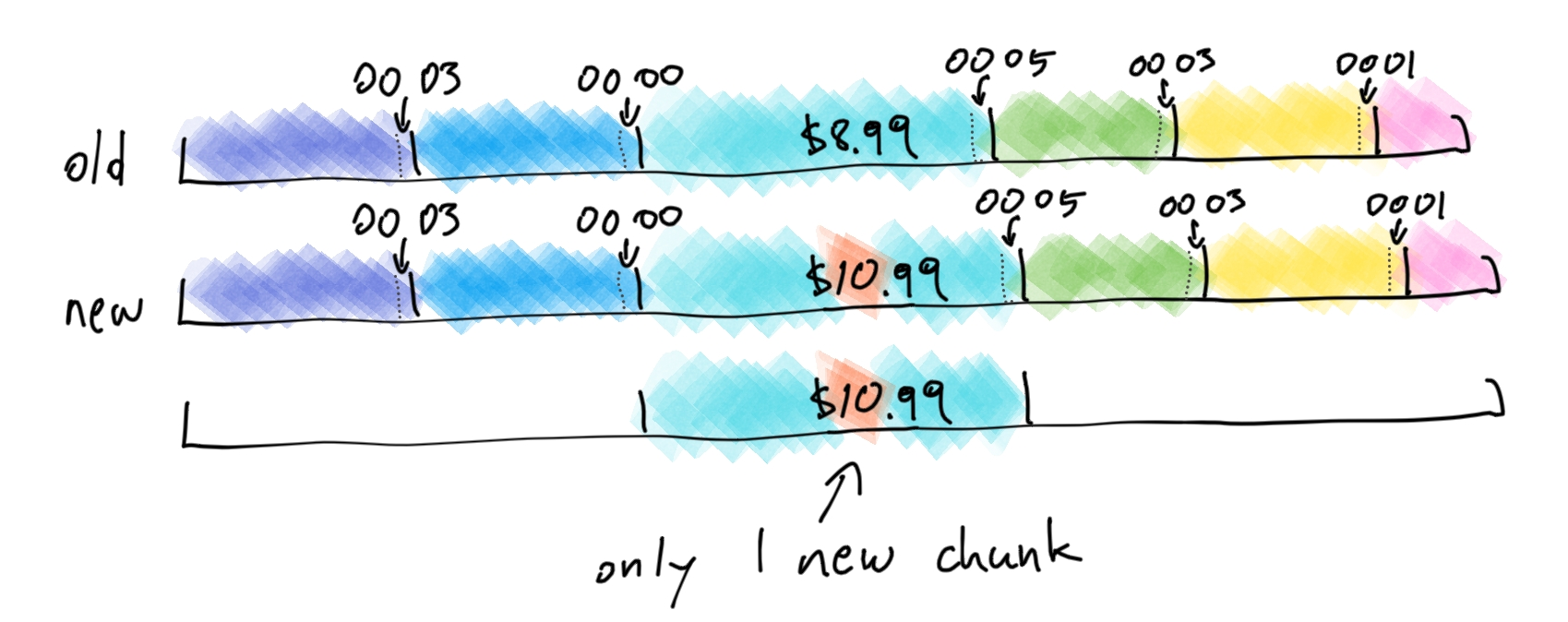
It's important to note that there are 2 sets of hashes being applied: first on every 64-byte window in the file to determine the chunk boundaries, and then on every entire chunk in order to check for duplication.
It works! We now have an algorithm that only stores new data when a page changes, and it only stores a small amount of data. But its performance is... lacking. We are still much slower than gzip. Hashes are expensive, and we are doing one hash for every byte in the file. How can we make it really cheap?
Enter the rolling hash. A rolling hash is a special type of hash function that can "slide" across the input and compute the hash of the next window from the previous.
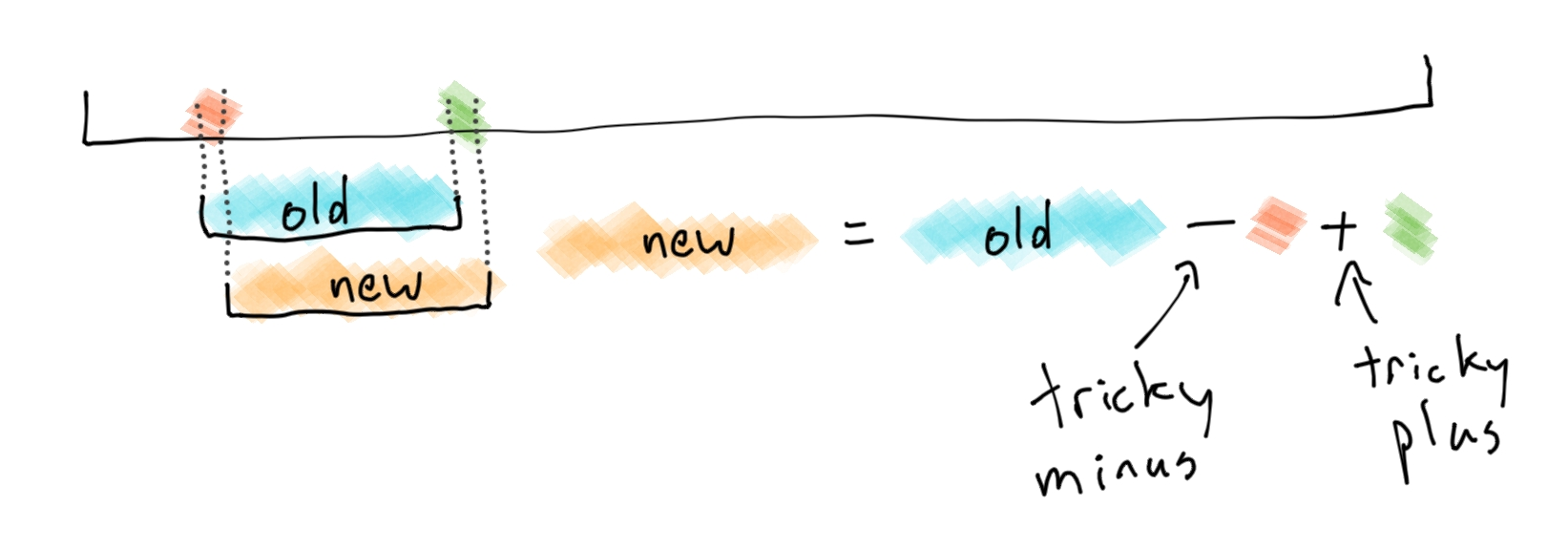
The best rolling hashes require just a small number of bit-shifts and additions for each "hash minus" and "hash plus" operation.
We now have our final algorithm, called content-defined chunking. It runs approximately as fast as gzip, depending on the hash functions chosen.
An excellent implementation to generate the chunks from a given sequence of bytes is FastCDC, and the associated paper can be found here.
Notes:
[1]: Specifically, this performs extremely well on any dataset that has high levels of duplication. For example, webpage archiving, file storage, backups, etc.
[2]: Zstd has a way to train compression dictionaries, which lets it maintain great compression ratios even on small chunks of data.
[3]: To make the math a little simpler, we are ignoring the 40-byte cost of a chunk's hash and id in our calculations, as well as the 32-byte cost of indexing the hash, since those costs are much smaller than the 2kB compressed content size.